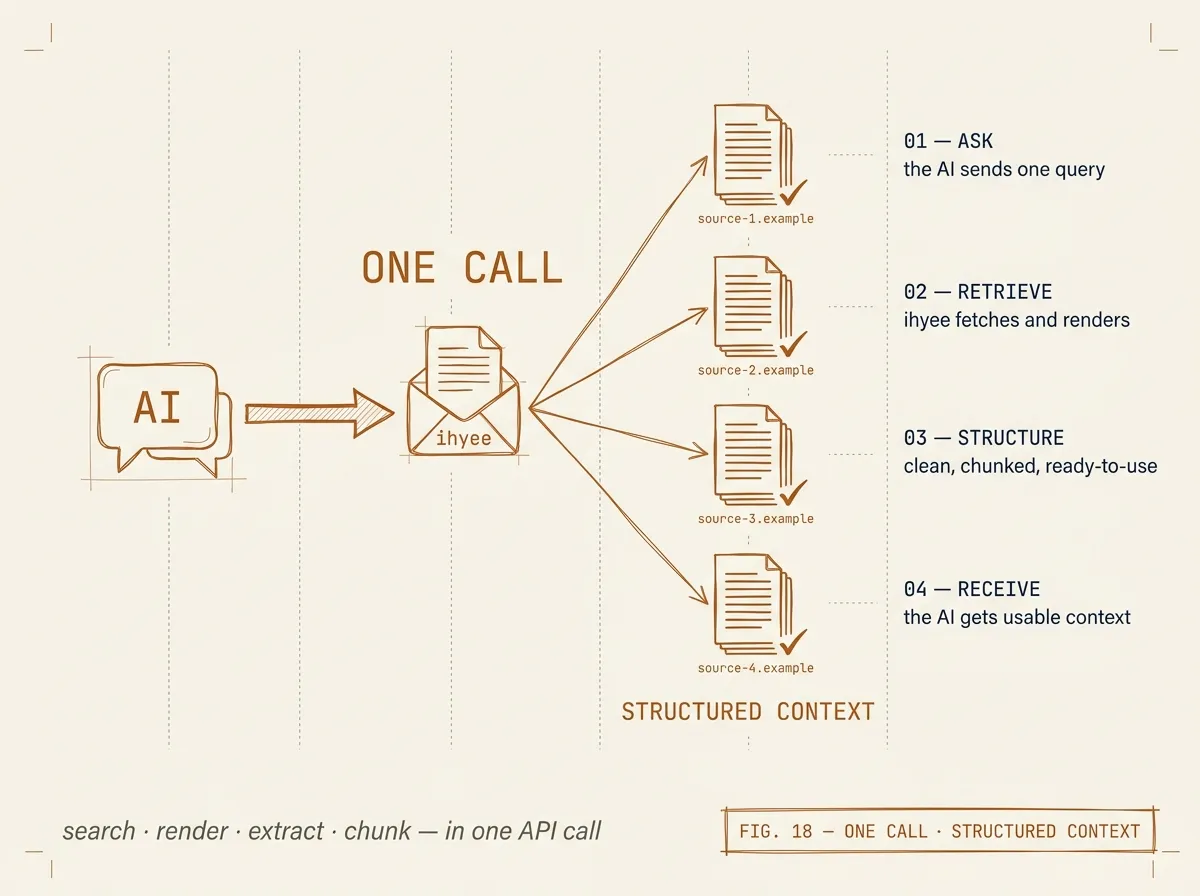
POST · /v1/search
Frontier-grade search with extracted content per result.
Operators (site:, filetype:, intitle:, "exact"), date filters (before / after / date_restrict), phrase filters (must_have, intext, allintext, and_condition). Content modes: summary, markdown, full_text, both, rag.