Pattern · Government · May 2026
Building integration that survives a four-hour satellite outage
How we designed offline-first integration for a Northern anchor institution: local-first state, queue-and-replay sync, idempotent integrations. The field worker never knows the link dropped, and the back-office systems reconcile cleanly when it returns.
The situation
A Canadian Northern institution operating across multiple territorial sites depended on satellite connectivity for the link between its field offices and its back-office systems. The link was reliable most of the time, but reliable did not mean continuous: weather events, equipment maintenance, and the occasional satellite reposition produced multi-hour outages on a regular basis. During the outage, every system that assumed a synchronous round-trip to the back office stopped working.
This was a daily operational problem, not a special case. Field workers — case managers, inspectors, intake clerks — would get partway through a workflow, the link would drop, and the workflow would either error out or, worse, leave the back-office systems in an inconsistent state when the link came back. The institution’s existing integration approach made the link a single point of failure for the entire site.
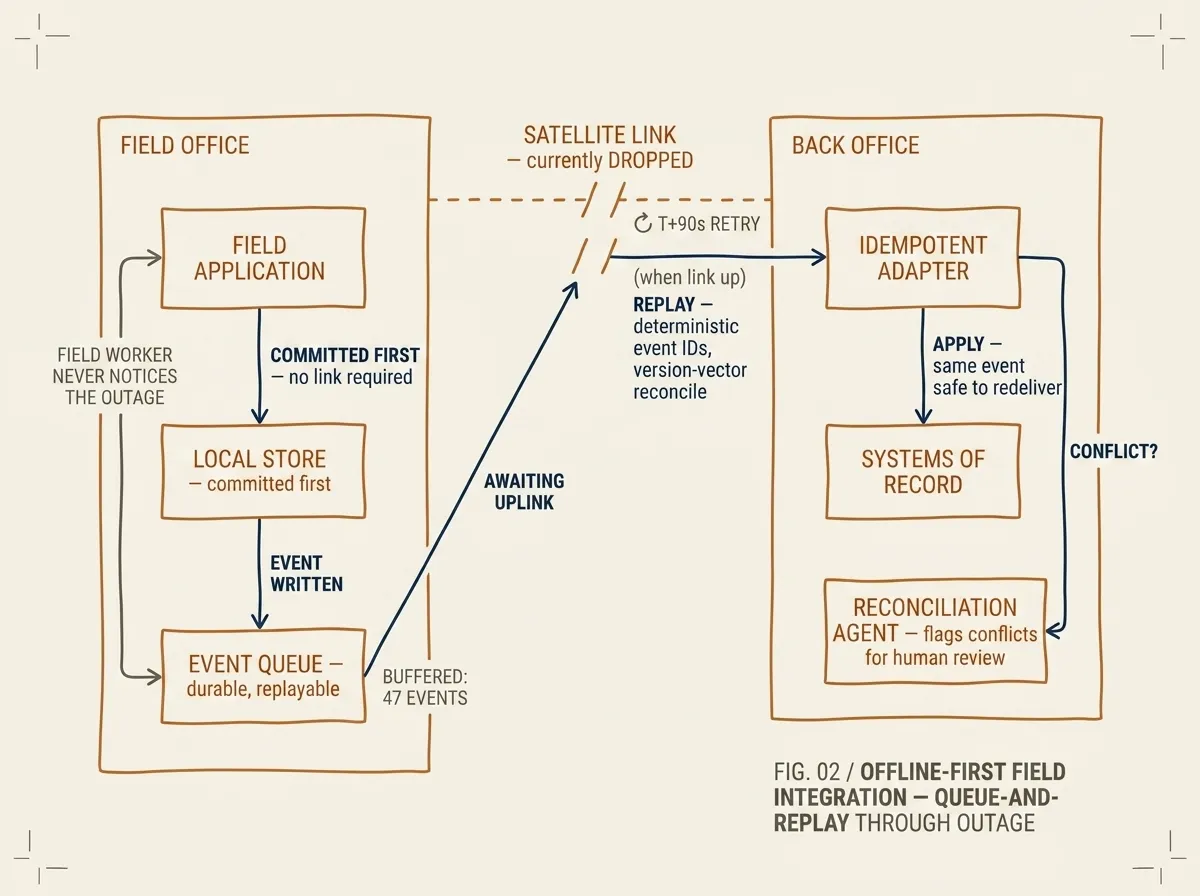
FIG. 02 / OFFLINE-FIRST FIELD INTEGRATION — committed-first to the local store, queued for upstream replay, idempotent on the back office. Field workflows continue uninterrupted; reconciliation completes within minutes of link restoration.
What we built
We rebuilt the field-to-back-office integration on three offline-first primitives. First, local state of record at the site: each field office got a single-box deployment running a local relational store and the field application. The field worker’s workflow committed to the local store immediately; the back-office sync was a downstream concern.
Second, queue-and-replay sync through a durable local event stream. Every state change at the field office produced an event on the local stream. A small relay process forwarded events upstream to the back-office stream when the link was up; when the link was down, events accumulated in the local stream’s storage. Replay was idempotent — we used deterministic event IDs and version-vector reconciliation, so re-delivery after the link restored did not double-apply changes.
Third, idempotent integration adapters at the back office. Every back-office connector was rewritten to handle the same event arriving more than once without changing the resulting state. This was not a small change — most existing connectors implicitly assumed exactly-once delivery — but it was a manageable one because we could test it against synthetic outage scenarios before any deployment touched a real site.
An agent runtime sat at the back-office layer to absorb the operational complexity. When a sync event referenced a record that had been modified at the back office during the outage, the agent flagged the conflict for human review rather than auto-merging. The decision-makers got plain-English summaries of what happened and what each option would mean.
How we tested it
Before the first production cutover, we ran the full integration through a test harness that simulated every connectivity failure mode the site team could describe: clean drops, brown-outs (link present but high packet loss), partial outages (one direction only), and recovery races (link comes back just as the field worker is mid-action). The test harness ran for two weeks against a shadow deployment connected to a copy of the back-office data.
The first production cutover happened during a planned maintenance window. The first real outage happened three days later. The field workers did not notice. The back-office reconciliation completed within four minutes of the link returning. The audit log captured every action and its eventual resolution.
What it produced
The institution stopped budgeting for the outage as a productivity event. Field workers continued their workflows during outages without changing how they worked. The back-office team stopped getting middle-of-the-night reconciliation pages. The audit trail was complete and gap-free, which mattered for the institution’s regulatory reporting.
The second-order benefit: the same architecture made it possible to deploy AI-assisted workflows at the field level (an agent runtime running locally against the local store), because the AI agent was no longer dependent on a synchronous link to a back-office model endpoint. That work is now in pilot.
What this pattern is good for
This pattern fits when three things are true: the deployment site has unreliable connectivity that cannot be made reliable by spending money, the field workflows are operationally important enough to justify a per-site infrastructure footprint, and the back-office systems can be modified to accept idempotent inbound events.
If the link is reliable most of the time and the rare outage is acceptable, simpler retry-and-give-up is cheaper. If the back-office systems cannot be modified to support idempotency, you’ll need a heavier reconciliation layer than this pattern provides. Otherwise: 10–14 weeks for the first site, with subsequent sites taking 3–4 weeks of deployment work each.
Recognise this pattern?
Tell us about yours.
If your problem rhymes with this one, scoping a project usually takes us less than a week. References available under NDA.
Talk to an engineer →