Pattern · Cross-sector · May 2026
How we got autoscaling, canary, and AI-powered ops on a 60-container stack without taking on a platform team
How we moved a Canadian operator's 60-container production stack off plain compose without making the conventional jump to a heavyweight orchestrator. Workloads stayed on the operator's own hosts; the orchestration control plane is operated as a managed service. No platform-engineering hire, no multi-component cluster, no foreign-cloud residency posture.

The situation
A Canadian operator was running approximately sixty production containers across a small fleet of hosts using compose profiles. The model had worked for the first thirty containers. By the time it reached sixty, the gaps were operationally limiting: a crashed container required a human to notice and restart it; rolling out a new revision meant a manual sequence of stops, image pulls, and starts that pulled an engineer out of other work for half an hour; secret rotation required editing environment files on each host; and there was no way to scale a workload to load without overprovisioning every replica.
The conventional next step — adopting a multi-component cluster orchestrator — failed three of the operator’s constraints. It required a dedicated platform engineer to run, which the headcount did not justify. It carried multiple gigabytes of base resident memory per node on a fleet where every gigabyte was already accounted for. And it could not attach a single container to multiple isolated networks, which the operator’s deployment model required for cleanly separating a public-facing surface from the back-end systems it integrated with. A foreign-cloud managed orchestrator was off the table for residency reasons before the conversation even began.
The operator wanted the operational outcomes — autoscaling, canary, secret management, RBAC, multi-network — without the heavyweight substrate or the platform-team requirement.
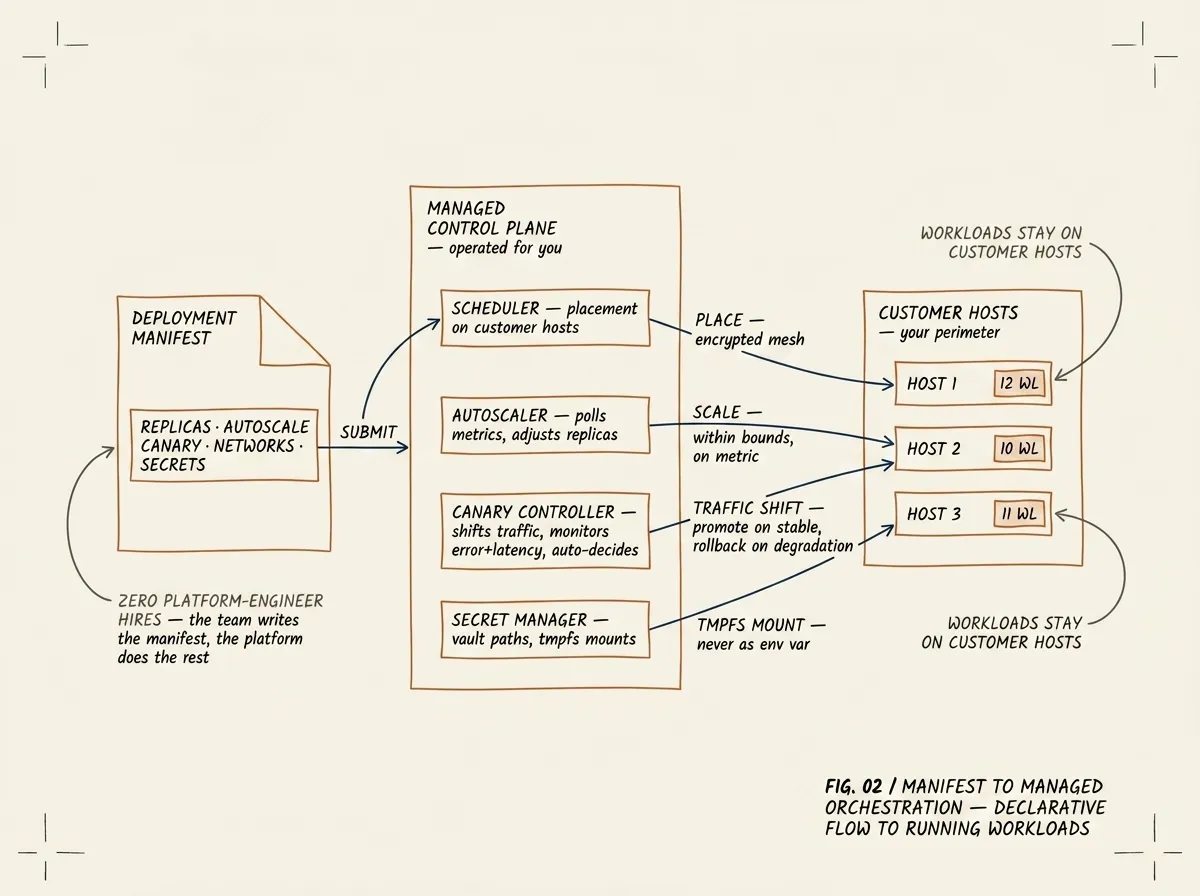
FIG. 02 / MANIFEST TO MANAGED ORCHESTRATION — the operator writes a single declarative manifest. The platform handles placement, autoscaling, canary traffic shifts, and tmpfs secret mounts. Workloads stay on the customer’s hosts; the control plane is operated as a managed service.
What we built
We enrolled the operator’s six hosts as nodes against a managed orchestration control plane, using a one-line agent installation per host that established an encrypted mesh back to the control plane. The workloads stayed on the operator’s hosts; the control plane — the scheduler, the reconciler, the autoscaler, the secret manager, the dashboard — runs as a managed service we operate.
We migrated workloads in four waves, lowest-risk first. Each migration converted a compose service into a deployment manifest: an extended compose syntax with declarative fields for replicas, autoscaling bounds, canary strategy, network attachments, and secret references. The deployment manifest is the only thing the operator’s team writes; everything else — placement, health monitoring, restart on crash, traffic shifting during rollouts, secret injection at start time — is handled by the platform.
For autoscaling we encoded each workload’s actual scaling behaviour: a target metric (CPU, request rate, or a custom expression), bounds, and a cooldown. The platform polls the metrics endpoint, evaluates the rules, and adjusts replica counts within bounds. For canary deployments we configured a small fraction of traffic to the new revision, an observation window measuring error rate and latency against the baseline, and an automatic decision: promote on stable metrics, roll back on degradation. For secrets we moved every credential from environment files to per-tenant vault paths; secrets mount on a memory-backed filesystem inside the container, so process listings, crash dumps, and runtime introspection no longer leak them.
The dashboard became the daily driver for operations work. The CLI exists for scripted tasks; it is not how the team interacts with the platform under normal conditions.
How we cut over without disruption
Cutover ran one workload at a time. Each workload was deployed against the new control plane in parallel with its compose original; traffic stayed on the original until a short operational window confirmed the new version was healthy. The platform’s per-workload work was minutes, not hours: a workload that used to need a thirty-to-sixty-minute manual sequence of stops, image pulls, and starts now took two to three minutes from manifest submission to running replicas. With the migration plan agreed and the configurations validated up front, the operator’s engineers ran the entire move — all sixty workloads — inside a single working day, with a soft rollback path to the compose definitions held open until the final workload was confirmed.
The compose definitions stayed in the repo as a rollback path until the final workload migrated. We have not used them since.
What this pattern is good for
This pattern works when three things are true: the operator is running workloads in a count range — roughly twenty to a few hundred containers — where compose is past its useful ceiling but a multi-component cluster orchestrator is structurally too much; the operator wants the operational outcomes (autoscaling, canary, secret management, multi-network, RBAC) without the platform-team requirement; and either residency, RAM ceiling, or operational simplicity is a hard constraint that the heavyweight alternative cannot meet.
If those three are true, the migration itself is short — under twelve hours of platform work for a stack of this size once the configuration is known — and the team operates the new substrate themselves once it’s done. The pattern is not sector-specific; we have applied it to telecom platform operators, energy edge sites, and government departments where the orchestration substrate had become the limiting factor without justifying a platform engineer of its own.
Recognise this pattern?
Tell us about yours.
If your problem rhymes with this one, scoping a project usually takes us less than a week. References available under NDA.
Talk to an engineer →